Таблицы сопряженности методы теории марковских цепей. Марковские цепи
Маркова цепь (Markov Chain) - марковский процесс с дискретным временем, заданный в измеримом пространстве.
Введение
Марковские случайные процессы названы по имени выдающегося русского математика А.А.Маркова (1856-1922), впервые начавшего изучение вероятностной связи случайных величин и создавшего теорию, которую можно назвать "динамикой вероятностей".
В дальнейшем основы этой теории явились исходной базой общей теории случайных процессов, а также таких важных прикладных наук, как теория диффузионных процессов, теория надежности, теория массового обслуживания и т.д. В настоящее время теория марковских процессов и ее приложения широко применяются в самых различных областях.
Благодаря сравнительной простоте и наглядности математического аппарата, высокой достоверности и точности получаемых решений, особое внимание марковские процессы приобрели у специалистов, занимающихся исследованием операций и теорией принятия оптимальных решений.
Простой пример: бросание монеты
Прежде чем дать описание общей схемы, обратимся к простому примеру. Предположим, что речь идет о последовательных бросаниях монеты при игре "в орлянку "; монета бросается в условные моменты времени t = 0, 1, ... и на каждом шаге игрок может выиграть ±1 с одинаковой вероятностью 1/2, таким образом в момент t его суммарный выигрыш есть случайная величина ξ(t) с возможными значениями j = 0, ±1, ...
При условии, что ξ(t) = k, на следующем шаге выигрыш будет уже равен ξ(t+1) = k ± 1, принимая указанные значения j = k ± 1 c одинаковой вероятностью 1/2.
Условно можно сказать, что здесь с соответствующей вероятностью происходит переход из состояния ξ(t) = k в состояние ξ(t+1) = k ± 1.
Формулы и определения
Обобщая этот пример, можно представить себе "систему" со счетным числом возможных "фазовых" состояний, которая с течением дискретного времени t = 0, 1, ... случайно переходит из состояния в состояние.
Пусть ξ(t) есть ее положение в момент t в результате цепочки случайных переходов
ξ(0) - ξ(1) - ... - ξ(t) - ... ... (1)
Формально обозначим все возможные состояния целыми i = 0, ±1, ... Предположим, что при известном состоянии ξ(t) = k на следующем шаге система переходит в состояние ξ(t+1) = j с условной вероятностью
p kj = P(ξ(t+1) = j|ξ(t) = k) ... (2)
независимо от ее поведения в прошлом, точнее, независимо от цепочки переходов (1) до момента t:
P(ξ(t+1) = j|ξ(0) = i, ..., ξ(t) = k) = P(ξ(t+1) = j|ξ(t) = k) при всех t, k, j ... (3) - марковское свойство.
Такую вероятностную схему называют однородной цепью Маркова со счетным числом состояний
- ее однородность состоит в том, что определенные в (2) переходные вероятности p kj
, ∑ j p kj = 1, k = 0, ±1, ..., не зависят от времени, т.е. P(ξ(t+1) = j|ξ(t) = k) = P ij - матрица вероятностей перехода
за один шаг не зависит от n.
Ясно, что P ij - квадратная матрица с неотрицательными элементами и единичными суммами по строкам.
Такая матрица (конечная или бесконечная) называется стохастической матрицей. Любая стохастическая матрица может служить матрицей переходных вероятностей.
На практике: доставка оборудования по округам
Предположим, что некая фирма осуществляет доставку оборудования по Москве: в северный округ (обозначим А), южный (В) и центральный (С). Фирма имеет группу курьеров, которая обслуживает эти районы. Понятно, что для осуществления следующей доставки курьер едет в тот район, который на данный момент ему ближе. Статистически было определено следующее:
1) после осуществления доставки в А следующая доставка в 30 случаях осуществляется в А, в 30 случаях - в В и в 40 случаях - в С;
2) после осуществления доставки в В следующая доставка в 40 случаях осуществляется в А, в 40 случаях - в В и в 20 случаях - в С;
3) после осуществления доставки в С следующая доставка в 50 случаях осуществляется в А, в 30 случаях - в В и в 20 случаях - в С.
Таким образом, район следующей доставки определяется только предыдущей доставкой.
Матрица вероятностей перехода будет выглядеть следующим образом:
Например, р 12 = 0.4 - это вероятность того, что после доставки в район В следующая доставка будет производиться в районе А.
Допустим, что каждая доставка с последующим перемещением в следующий район занимает 15 минут. Тогда, в соответствии со статистическими данными, через 15 минут 30% из курьеров, находившихся в А, будут в А, 30% будут в В и 40% - в С.
Так как в следующий момент времени каждый из курьеров обязательно будет в одном из округов, то сумма по столбцам равна 1. И поскольку мы имеем дело с вероятностями, каждый элемент матрицы 0<р ij <1.
Наиболее важным обстоятельством, которое позволяет интерпретировать данную модель как цепь Маркова, является то, что местонахождние курьера в момент времени t+1 зависит только от местонахождения в момент времени t.
Теперь зададим простой вопрос: если курьер стартует из С, какова вероятность того, что осуществив две доставки, он будет в В, т.е. как можно достичь В в 2 шага? Итак, существует несколько путей из С в В за 2 шага:
1) сначала из С в С и потом из С в В;
2) С-->B и B-->B;
3) С-->A и A-->B.
Учитывая правило умножения независимых событий, получим, что искомая вероятность равна:
P = P(CA)*P(AB) + P(CB)*P(BB) + P(CC)*P(CB)
Подставляя числовые значения:
P = 0.5*0.3 + 0.3*0.4 + 0.2*0.3 = 0.33
Полученный результат говорит о том, что если курьер начал работу из С, то в 33 случаях из 100 он будет в В через две доставки.
Ясно, что вычисления просты, но если Вам необходимо определить вероятность через 5 или 15 доставок - это может занять довольно много времени.
Покажем более простой способ вычисления подобных вероятностей. Для того, чтобы получить вероятности перехода из различных состояний за 2 шага, возведем матрицу P в квадрат:

Тогда элемент (2, 3) - это вероятность перехода из С в В за 2 шага, которая была получена выше другим способом. Заметим, что элементы в матрице P 2 также находятся в пределах от 0 до 1, и сумма по столбцам равна 1.
Т.о. если Вам необходимо определить вероятности перехода из С в В за 3 шага:
1 способ. p(CA)*P(AB) + p(CB)*P(BB) + p(CC)*P(CB) = 0.37*0.3 + 0.33*0.4 + 0.3*0.3 = 0.333, где p(CA) - вероятность перехода из С в А за 2 шага (т.е. это элемент (1, 3) матрицы P 2).
2 способ. Вычислить матрицу P 3:

Матрица переходных вероятностей в 7 степени будет выглядеть следующим образом:

Легко заметить, что элементы каждой строки стремятся к некоторым числам. Это говорит о том, что после достаточно большого количества доставок уж не имеет значение в каком округе курьер начал работу. Т.о. в конце недели приблизительно 38,9% будут в А, 33,3% будут в В и 27,8% будут в С.
Подобная сходимость гарантировано имеет место, если все элементы матрицы переходных вероятностей принадлежат интервалу (0, 1).
1 июня 2016 в 16:31Разработка класса для работы с цепями Маркова
- C++ ,
- Алгоритмы
Сегодня я хотел бы поведать вам о написании класса для упрощения работы с цепями Маркова.
Прошу под кат.
Начальные знания:
Представление графов в форме матрицы смежности, знание основных понятий о графах. Знание C++ для практической части.
Теория
Це́пь Ма́ркова - последовательность случайных событий с конечным или счётным числом исходов, характеризующаяся тем свойством, что, говоря нестрого, при фиксированном настоящем будущее независимо от прошлого. Названа в честь А. А. Маркова (старшего).
Если говорить простыми словами, то Цепь Маркова - это взвешенный граф. В его вершинах находятся события, а в качестве веса ребра, соединяющего вершины A и B - вероятность того, что после события A последует событие B.
О применении цепей Маркова написано довольно много статей, мы же продолжим разработку класса.
Приведу пример цепи Маркова:
В дальнейшем мы будем рассматривать в качестве примера эту схему.
Очевидно, что если из вершины A есть только одно исходящее ребро, то его вес будет равен 1.
Обозначения
В вершинах у нас находятся события (от A, B, C, D, E...). На ребрах вероятность того, что после i-го события будет событие j > i. Для условности и удобства я пронумеровал вершины (№1, №2 и т.д).Матрицей будем называть матрицу смежности ориентированного взвешенного графа, которым изображаем цепь Маркова. (об этом далее). В данном частном случае эта матрица называется также матрицей переходных вероятностей или просто матрицей перехода.
Матричное представление цепи Маркова
Представлять цепи Маркова мы будем при помощи матрицы, именно той матрицы смежности, которой представляем графы.Напомню:
Матрица смежности графа G с конечным числом вершин n (пронумерованных числами от 1 до n) - это квадратная матрица A размера n, в которой значение элемента aij равно числу рёбер из i-й вершины графа в j-ю вершину.
Подробнее о матрицах смежности - в курс дискретной математики.
В нашем случае матрица будет иметь размер 10x10, напишем ее:
0 50 0 0 0 0 50 0 0 0
0 0 80 20 0 0 0 0 0 0
0 0 0 0 100 0 0 0 0 0
0 0 0 0 100 0 0 0 0 0
0 0 0 0 0 100 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 70 30 0
0 0 0 0 0 0 0 0 0 100
0 0 0 0 0 0 0 0 0 100
0 0 0 0 0 100 0 0 0 0
Идея
Посмотрите внимательнее на нашу матрицу. В каждой строке у нас есть ненулевые значения в тех столбцах, чей номер совпадает с последующим событием, а само ненулевое значение - вероятность, что это событие наступит.Таким образом, мы имеем значения вероятности наступления события с номером, равным номеру столбца после события с номером, равным строки .
Те кто знают теорию вероятностей могли догадаться, что каждая строка - это функция распределения вероятностей.
Алгоритм обхода цепи Маркова
1) инициализируем начальную позицию k нулевой вершиной.2) Если вершина не конечная, то генерируем число m от 0...n-1 на основе распределения вероятности в строке k матрицы, где n - число вершин, а m - номер следующего события (!). Иначе выходим
3) Номер текующей позиции k приравниваем к номеру сгенерированной вершине
4) На шаг 2
Замечание: вершина конечная если распределение вероятностей нулевое (см. 6-ю строку в матрице).
Довольно изящный алгоритм, так ведь?
Реализация
В эту статью я хочу отдельно вынести код реализации описанного обхода. Инициализация и заполнение цепи Маркова не несут особого интереса (полный код см. в конце).Реализация алгоритма обхода
template
Данный алгоритм выглядит особенно просто благодаря особенностям контейнера discrete_distribution . На словах описать, как работает этот контейнер довольно сложно, поэтому возьмем в пример 0-ю строку нашей матрицы:
0 50 0 0 0 0 50 0 0 0
В результате работы генератора он вернет либо 1, либо 6 с вероятностями в 0.5 для каждой. То есть возвращает номер столбца (что эквивалентно номеру вершины в цепи) куда следует продолжить движение дальше.
Пример программы, которая использует класс:
Реализация программы, которая делает обход цепи Маркова из примера
#include
Пример вывода, который генерирует программа: по себе, а отчасти рассматриваем мы ее из-за того, что ее изложение не требует введения большого количества новых терминов.
Рассмотрим задачу об осле, стоящем точно между двумя копнами: соломы ржи и соломы пшеницы (рис. 10.5).
Осел стоит между двумя копнами: "Рожь" и "Пшеница" (рис. 10.5). Каждую минуту он либо передвигается на десять метров в сторону первой копны (с вероятностью ), либо в сторону второй копны (с вероятностью ), либо остается там, где стоял (с вероятностью ); такое поведение называется одномерным случайным блужданием. Будем предполагать, что обе копны являются "поглощающими" в том смысле, что если осел подойдет к одной из копен, то он там и останется. Зная расстояние между двумя копнами и начальное положение осла, можно поставить несколько вопросов, например: у какой копны он очутится с большей вероятностью и какое наиболее вероятное время ему понадобится, чтобы попасть туда?

Рис. 10.5.
Чтобы исследовать эту задачу подробнее, предположим, что расстояние
между
копнами равно пятидесяти метрам и что наш осел находится в двадцати метрах
от копны "Пшеницы". Если места, где можно остановиться, обозначить
через ![]() ( - сами
копны), то его начальное положение можно задать вектором -я
компонента которого равна вероятности того, что он первоначально находится
в . Далее, по
прошествии одной минуты вероятности его
местоположения описываются вектором , а через
две минуты - вектором . Ясно, что
непосредственное вычисление
вероятности его нахождения в заданном месте по
прошествии минут становится затруднительным. Оказалось, что
удобнее всего ввести для этого матрицу перехода
.
( - сами
копны), то его начальное положение можно задать вектором -я
компонента которого равна вероятности того, что он первоначально находится
в . Далее, по
прошествии одной минуты вероятности его
местоположения описываются вектором , а через
две минуты - вектором . Ясно, что
непосредственное вычисление
вероятности его нахождения в заданном месте по
прошествии минут становится затруднительным. Оказалось, что
удобнее всего ввести для этого матрицу перехода
.

Пусть - вероятность того, что он переместится из в за одну минуту. Например, и . Эти вероятности называются вероятностями перехода , а -матрицу называют матрицей перехода . Заметим, что каждый элемент матрицы неотрицателен и что сумма элементов любой из строк равна единице. Из всего этого следует, что - начальный вектор -строка, определенный выше, местоположение осла по прошествии одной минуты описывается вектором-строкой , а после минут - вектором . Другими словами, -я компонента вектора определяет вероятность того, что по истечении минут осел оказался в .
Можно обобщить эти понятия. Назовем вектором вероятностей вектор -строку, все компоненты которого неотрицательны и дают в сумме единицу. Тогда матрица перехода определяется как квадратная матрица , в которой каждая строка является вектором вероятностей. Теперь можно определить цепь Маркова (или просто цепь) как пару , где есть - матрица перехода , а есть - вектор -строка. Если каждый элемент из рассматривать как вероятность перехода из позиции в позицию , а - как начальный вектор вероятностей, то придем к классическому понятию дискретной стационарной цепи Маркова , которое можно найти в книгах по теории вероятностей (см. Феллер В. Введение в теорию вероятностей и ее приложения. Т.1. М.: Мир. 1967) Позиция обычно называется состоянием цепи . Опишем различные способы их классификации.
Нас будет интересовать следующее: можно ли попасть из одного данного состояния в другое, и если да, то за какое наименьшее время. Например, в задаче об осле из в можно попасть за три минуты и вообще нельзя попасть из в . Следовательно, в основном мы будем интересоваться не самими вероятностями , а тем, положительны они или нет. Тогда появляется надежда, что все эти данные удастся представить в виде орграфа , вершины которого соответствуют состояниям, а дуги указывают на то, можно ли перейти из одного состояния в другое за одну минуту. Более точно, если каждое состояние представлено соответствующей ему вершиной).
Цепь Маркова – череда событий, в которой каждое последующее событие зависит от предыдущего. В статье мы подробнее разберём это понятие.
Цепь Маркова – это распространенный и довольно простой способ моделирования случайных событий. Используется в самых разных областях, начиная генерацией текста и заканчивая финансовым моделированием. Самым известным примером является SubredditSimulator . В данном случае Цепь Маркова используется для автоматизации создания контента во всем subreddit.
Цепь Маркова понятна и проста в использовании, т. к. она может быть реализована без использования каких-либо статистических или математических концепций. Цепь Маркова идеально подходит для изучения вероятностного моделирования и Data Science.
Сценарий
Представьте, что существует только два погодных условия: может быть либо солнечно, либо пасмурно. Всегда можно безошибочно определить погоду в текущий момент. Гарантированно будет ясно или облачно.
Теперь вам захотелось научиться предсказывать погоду на завтрашний день. Интуитивно вы понимаете, что погода не может кардинально поменяться за один день. На это влияет множество факторов. Завтрашняя погода напрямую зависит от текущей и т. д. Таким образом, для того чтобы предсказывать погоду, вы на протяжении нескольких лет собираете данные и приходите к выводу, что после пасмурного дня вероятность солнечного равна 0,25. Логично предположить, что вероятность двух пасмурных дней подряд равна 0,75, так как мы имеем всего два возможных погодных условия.

Теперь вы можете прогнозировать погоду на несколько дней вперед, основываясь на текущей погоде.
Этот пример показывает ключевые понятия цепи Маркова. Цепь Маркова состоит из набора переходов, которые определяются распределением вероятностей, которые в свою очередь удовлетворяют Марковскому свойству.
Обратите внимание, что в примере распределение вероятностей зависит только от переходов с текущего дня на следующий. Это уникальное свойство Марковского процесса – он делает это без использования памяти. Как правило, такой подход не способен создать последовательность, в которой бы наблюдалась какая-либо тенденция. Например, в то время как цепь Маркова способна сымитировать стиль письма, основанный на частоте использования какого-то слова, она не способна создать тексты с глубоким смыслом, так как она может работать только с большими текстами. Именно поэтому цепь Маркова не может производить контент, зависящий от контекста.
Модель
Формально, цепь Маркова – это вероятностный автомат. Распределение вероятностей переходов обычно представляется в виде матрицы. Если цепь Маркова имеет N возможных состояний, то матрица будет иметь вид N x N, в которой запись (I, J) будет являться вероятностью перехода из состояния I в состояние J. Кроме того, такая матрица должна быть стохастической, то есть строки или столбцы в сумме должны давать единицу. В такой матрице каждая строка будет иметь собственное распределение вероятностей.

Общий вид цепи Маркова с состояниями в виде окружностей и ребрами в виде переходов.

Примерная матрица перехода с тремя возможными состояниями.
Цепь Маркова имеет начальный вектор состояния, представленный в виде матрицы N x 1. Он описывает распределения вероятностей начала в каждом из N возможных состояний. Запись I описывает вероятность начала цепи в состоянии I.
Этих двух структур вполне хватит для представления цепи Маркова.
Мы уже обсудили, как получить вероятность перехода из одного состояния в другое, но что насчет получения этой вероятности за несколько шагов? Для этого нам необходимо определить вероятность перехода из состояния I в состояние J за M шагов. На самом деле это очень просто. Матрицу перехода P можно определить вычислением (I, J) с помощью возведения P в степень M. Для малых значений M это можно делать вручную, с помощью повторного умножения. Но для больших значений M, если вы знакомы с линейной алгеброй, более эффективным способом возведения матрицы в степень будет сначала диагонализировать эту матрицу.
Цепь Маркова: заключение
Теперь, зная, что из себя представляет цепь Маркова, вы можете легко реализовать её на одном из языков программирования. Простые цепи Маркова являются фундаментом для изучения более сложных методов моделирования.
Способы математических описаний марковских случайных процессов в системе с дискретными состояниями (ДС) зависят от того, в какие моменты времени (заранее известные или случайные) могут происходить переходы системы из состояния в состояние.
Если переход системы из состояния в состояние возможен в заранее фиксированные моменты времени, имеем дело со случайным марковским процессом с дискретным временем.
Если переход возможен в любой случайный момент времени, то имеем дело со случайным марковским процессом с непрерывным временем.
Пусть имеется физическая система S
, которая может находиться в n
состояниях S
1 , S
2 , …, S n
. Переходы из состояния в состояние возможны только в моменты времени t
1 , t
2 , …, t k
, назовём эти моменты времени шагами. Будем рассматривать СП в системе S
как функцию целочисленного аргумента 1, 2, …, k
, где аргументом является номер шага.
Пример: S
1 → S
2 → S
3 → S
2 .
Условимся обозначать S i
( k
) – событие, состоящее в том, что после k
шагов система находится в состоянии S i
.
При любом k
события S 1 ( k
) , S 2 ( k
) ,…, S n
( k
) образуют полную группу событий
и являются несовместными.
Процесс в системе можно представить как цепочку событий.
Пример:S
1 (0) , S
2 (1) , S 3 (2) , S 5 (3) ,….
Такая последовательность называется марковской цепью
, если для каждого шага вероятность перехода из любого состояния S i
в любое состояние S j
не зависит от того, когда и как система пришла в состояние S i
.
Пусть в любой момент времени после любого k
-го шага система S
может находиться в одном из состояний S
1 , S
2 , …, S n
, т. е. может произойти одно событие из полной группы событий: S
1 ( k
) , S 2 ( k
) , …, S n
( k
) . Обозначим вероятности этих событий:
P
1 (1) = P
(S
1 (1)); P
2 (1) = P
(S
2 (1)); …; P n
(1) = P
(S n
( k
));
P
1 (2) = P
(S
1 (2)); P
2 (2) = P
(S 2 (2)); …; P n
(2) = P
(S n
(2));
P
1 (k
) = P
(S
1 (k
)); P
2 (k
) = P
(S
2 (k
)); …; P n
(k
) = P
(S n
(k
)).
Легко заметить, что для каждого номера шага выполняется условие
P
1 (k
) + P
2 (k
) +…+ P n
(k
) = 1.
Назовём эти вероятности вероятностями состояний
.следовательно, задача будет звучать следующим образом: найти вероятности состояний системы для любого k
.
Пример.
Пусть имеется какая-то система, которая может находиться в любом из шести состояний. тогда процессы, происходящие в ней, можно изобразить либо в виде графика изменения состояния системы (рис. 7.9, а
), либо в виде графа состояний системы (рис. 7.9, б
).
а) 
Рис. 7.9
Также процессы в системе можно изобразить в виде последовательности состояний: S
1 , S
3 , S
2 , S
2 , S
3 , S
5 , S
6 , S
2 .
Вероятность состояния на (k
+ 1)-м шаге зависит только от состояния на k-
м шаге.
Для любого шага k
существуют какие-то вероятности перехода системы из любого состояния в любое другое состояние, назовем эти вероятности переходными вероятностями марковской цепи.
Некоторые из этих вероятностей будут равны 0, если переход из одного состояния в другое невозможен за один шаг.
Марковская цепь называется однородной
, если переходные состояния не зависят от номера шага, в противном случае она называется неоднородной
.
Пусть имеется однородная марковская цепь и пусть система S
имеет n
возможных состояний: S
1 , …, S n
. Пусть для каждого состояния известна вероятность перехода в другое состояние за один шаг, т. е. P ij
(из S i
в S j
за один шаг), тогда мы можем записать переходные вероятности в виде матрицы.
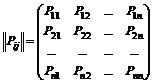 . (7.1)
. (7.1)
По диагонали этой матрицы расположены вероятности того, что система переходит из состояния S i
в то же состояние S i
.
Пользуясь введенными ранее событиями ![]() , можно переходные вероятности записать как условные вероятности:
, можно переходные вероятности записать как условные вероятности:
![]() .
.
Очевидно, что сумма членов ![]() в каждой строке матрицы (1) равна единице, поскольку события
в каждой строке матрицы (1) равна единице, поскольку события ![]() образуют полную группу несовместных событий.
образуют полную группу несовместных событий.
При рассмотрении марковских цепей, так же как и при анализе марковского случайного процесса, используются различные графы состояний (рис. 7.10).

Рис. 7.10
Данная система может находиться в любом из шести состояний, при этом P ij
– вероятность перехода системы из состояния S i
в состояние S j
. Для данной системы запишем уравнения, что система находилась в каком-либо состоянии и из него за время t
не вышла:

В общем случае марковская цепь является неоднородной, т. е. вероятность P ij
меняется от шага к шагу. Предположим, что задана матрица вероятностей перехода на каждом шаге, тогда вероятность того, что система S
на k
-м шаге будет находиться в состоянии S i
, можно найти по формуле
![]()
Зная матрицу переходных вероятностей и начальное состояние системы, можно найти вероятности состояний ![]() после любого k
-го шага. Пусть в начальный момент времени система находится в состоянии S m
. Тогда для t = 0
после любого k
-го шага. Пусть в начальный момент времени система находится в состоянии S m
. Тогда для t = 0
.
Найдем вероятности после первого шага. Из состояния S m
система перейдет в состояния S
1 , S
2 и т. д. с вероятностями P m
1 , P m
2 , …, P mm
, …, P mn
. Тогда после первого шага вероятности будут равны
. (7.2)
Найдем вероятности состояния после второго шага: . Будем вычислять эти вероятности по формуле полной вероятности с гипотезами:
![]() .
.
Гипотезами будут следующие утверждения:
- после первого шага система была в состоянии S 1 -H 1 ;
- после второго шага система была в состоянии S 2 -H 2 ;
- после n -го шага система была в состоянии S n -H n .

Вероятность любого состояния после второго шага:
![]() (7.3)
(7.3)
В формуле (7.3) суммируются все переходные вероятности P ij
, но учитываются только отличные от нуля. Вероятность любого состояния после k
-го шага:
![]() (7.4)
(7.4)
Таким образом, вероятность состояния после k
-го шага определяется по рекуррентной формуле (7.4) через вероятности (k –
1)-го шага.
Задача 6.
Задана матрица вероятностей перехода для цепи Маркова за один шаг. Найти матрицу перехода данной цепи за три шага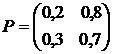 .
.
Решение.
Матрицей перехода системы называют матрицу, которая содержит все переходные вероятности этой системы:
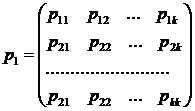
В каждой строке матрицы помещены вероятности событий (перехода из состояния i
в состояние j
), которые образуют полную группу, поэтому сумма вероятностей этих событий равна единице:
![]()
Обозначим через p ij (n) вероятность того, что в результате n шагов (испытаний) система перейдет из состояния i в состояние j . Например p 25 (10) - вероятность перехода из второго состояния в пятое за десять шагов. Отметим, что при n=1 получаем переходные вероятности p ij (1)=p ij .
Перед нами поставлена задача: зная переходные вероятности p ij , найти вероятности p ij (n) перехода системы из состояния i
в состояние j
заn
шагов. Для этого введем промежуточное (между i
и j
) состояние r
. Другими словами, будем считать, что из первоначального состояния i
за m
шагов система перейдет в промежуточное состояние r
с вероятностью p ij (n-m) , после чего, за оставшиеся n-m шагов из промежуточного состояния r она перейдет в конечное состояние j с вероятностью p ij (n-m) . По формуле полной вероятности получаем:
![]() .
.
Эту формулу называют равенством Маркова. С помощью этой формулы можно найти все вероятности p ij (n) , а, следовательно, и саму матрицу P n . Так как матричное исчисление ведет к цели быстрее, запишем вытекающее из полученной формулы матричное соотношение в общем виде.
Вычислим матрицу перехода цепи Маркова за три шага, используя полученную формулу:
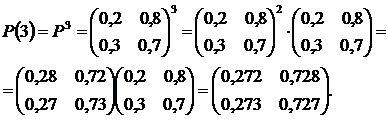
Ответ:
 .
.
Задача №1
. Матрица вероятностей перехода цепи Маркова имеет вид:
 .
.
Распределение по состояниям в момент времени t=0 определяется вектором:
π 0 =(0.5; 0.2; 0.3)
Найти:
а) распределение по состояниям в моменты t=1,2,3,4 .
в) стационарное распределение.










