Математическое ожидание случайной. Математическое ожидание непрерывной случайной величины
Каждая, отдельно взятая величина полностью определяется своей функцией распределения. Также, для решения практических задач хватает знать несколько числовых характеристик, благодаря которым появляется возможность представить основные особенности случайной величины в краткой форме.
К таким величинам относят в первую очередь математическое ожидание и дисперсия .
Математическое ожидание — среднее значение случайной величины в теории вероятностей. Обозначается как .
Самым простым способом математическое ожидание случайной величины Х(w)
, находят как интеграл
Лебега
по отношению к вероятностной мере Р
исходном
вероятностном пространстве
![]()
Еще найти математическое ожидание величины можно как интеграл Лебега от х по распределению вероятностей Р Х величины X :
![]()
где - множество всех возможных значений X .
Математическое ожидание функций от случайной величины X находится через распределение Р Х . Например , если X - случайная величина со значениями в и f(x) - однозначная борелевская функция Х , то:
Если F(x) - функция распределения X , то математическое ожидание представимо интегралом Лебега - Стилтьеса (или Римана - Стилтьеса):
![]()
при этом интегрируемость X в смысле (* ) соответствует конечности интеграла
![]()
В конкретных случаях, если X имеет дискретное распределение с вероятными значениями х k , k=1, 2 , . , и вероятностями , то
![]()
если X имеет абсолютно непрерывное распределение с плотностью вероятности р(х) , то
![]()
при этом существование математического ожидания равносильно абсолютной сходимости соответствующего ряда или интеграла.
Свойства математического ожидания случайной величины.
- Математическое ожидание постоянной величины равно этой величине:
C - постоянная;
- M=C.M[X]
- Математическое ожидание суммы случайно взятых величин равно сумме их математических ожиданий:
![]()
- Математическое ожидание произведения независимых случайно взятых величин = произведению их математических ожиданий:
M=M[X]+M[Y]
если X и Y независимы.
если сходится ряд:
![]()
Алгоритм вычисления математического ожидания.
Свойства дискретных случайных величин: все их значения можно перенумеровать натуральными числами; каждому значению приравнять отличную от нуля вероятность.
1. По очереди перемножаем пары: x i на p i .
2. Складываем произведение каждой пары x i p i .
Напрмер , для n = 4 :
Функция распределения дискретной случайной величины ступенчатая, она возрастает скачком в тех точках, вероятности которых имеют положительный знак.
Пример: Найти математическое ожидание по формуле.
Следующим по важности свойством случайной величины вслед за математическим ожиданием является ее дисперсия, определяемая как средний квадрат отклонения от среднего:
Если обозначить через то дисперсия VX будет ожидаемым значением Это характеристика „разброса" распределения X.
В качестве простого примера вычисления дисперсии предположим, что нам только что сделали предложение, от которого мы не в силах отказаться: некто подарил нам два сертификата для участия в одной лотерее. Устроители лотереи продают каждую неделю по 100 билетов, участвующих в отдельном тираже. В тираже выбирается один их этих билетов посредством равномерного случайного процесса - каждый билет имеет равные шансы быть выбранным - и обладатель этого счастливого билета получает сто миллионов долларов. Остальные 99 владельцев лотерейных билетов не выигрывают ничего.
Мы можем использовать подарок двумя способами: купить или два билета в одной лотерее, или по одному для участия в двух разных лотереях. Какая стратегия лучше? Попытаемся провести анализ. Для этого обозначим через случайные величины, представляющие размер нашего выигрыша по первому и второму билету. Ожидаемое значение в миллионах, равно
и то же самое справедливо для Ожидаемые значения аддитивны, поэтому наш средний суммарный выигрыш составит
независимо от принятой стратегии.
Тем не менее, две стратегии выглядят различными. Выйдем за рамки ожидаемых значений и изучим полностью распределение вероятностей

Если мы купим два билета в одной лотерее, то наши шансы не выиграть ничего составят 98% и 2% - шансы на выигрыш 100 миллионов. Если же мы купим билеты на разные тиражи, то цифры будут такими: 98.01% - шанс не выиграть ничего, что несколько больше, чем ранее; 0.01% - шанс выиграть 200 миллионов, также чуть больше, чем было ранее; и шанс выиграть 100 миллионов теперь составляет 1.98%. Таким образом, во втором случае распределение величины несколько более разбросано; среднее значение, 100 миллионов долларов, несколько менее вероятно, тогда как крайние значения более вероятны.
Именно это понятие разброса случайной величины призвана отразить дисперсия. Мы измеряем разброс через квадрат отклонения случайной величины от ее математического ожидания. Таким образом, в случае 1 дисперсия составит
в случае 2 дисперсия равна
Как мы и ожидали, последняя величина несколько больше, поскольку распределение в случае 2 несколько более разбросано.
Когда мы работаем с дисперсиями, то все возводится в квадрат, так что в результате могут получиться весьма большие числа. (Множитель есть один триллион, это должно впечатлить
даже привычных к крупным ставкам игроков.) Для преобразования величин в более осмысленную исходную шкалу часто извлекают квадратный корень из дисперсии. Полученное число называется стандартным отклонением и обычно обозначается греческой буквой а:
Стандартные отклонения величины для наших двух лотерейных стратегий составят . В некотором смысле второй вариант примерно на 71247 долларов рискованнее.
Каким образом дисперсия помогает в выборе стратегии? Это не ясно. Стратегия с большей дисперсией рискованнее; но что лучше для нашего кошелька - риск или безопасная игра? Пусть у нас есть возможность купить не два билета, а все сто. Тогда мы могли бы гарантировать выигрыш в одной лотерее (и дисперсия была бы нулевой); или же можно было сыграть в сотне разных тиражей, ничего не получая с вероятностью зато имея ненулевой шанс на выигрыш вплоть до долларов. Выбор одной из этих альтернатив лежит за рамками этой книги; все, что мы можем сделать здесь,- это объяснить, как произвести подсчеты.
В действительности имеется более простой способ вычисления дисперсии, чем прямое использование определения (8.13). (Есть все основания подозревать здесь какую-то скрытую от глаз математику; иначе с чего бы дисперсия в лотерейных примерах оказалась целым кратным Имеем
поскольку - константа; следовательно,
„Дисперсия есть среднее значение квадрата минус квадрат среднего значения"
Например, в задаче про лотерею средним значением оказывается или Вычитание (квадрата среднего) дает результаты, которые мы уже получили ранее более трудным путем.
Есть, однако, еще более простая формула, применимая, когда мы вычисляем для независимых X и Y. Имеем

поскольку, как мы знаем, для независимых случайных величин Следовательно,

„Дисперсия суммы независимых случайных величин равняется сумме их дисперсий" Так, например, дисперсия суммы, которую можно выиграть на один лотерейный билет, равняется
Следовательно, дисперсия суммарного выигрыша по двум лотерейным билетам в двух различных (независимых) лотереях составит Соответствующее значение дисперсии для независимых лотерейных билетов будет
Дисперсия суммы очков, выпавших на двух кубиках, может быть получена по той же формуле, поскольку есть сумма двух независимых случайных величин. Имеем
для правильного кубика; следовательно, случае смещенного центра масс
следовательно, если у обоих кубиков центр масс смещен. Заметьте, что в последнем случае дисперсия больше, хотя принимает среднее значение 7 чаще, чем в случае правильных кубиков. Если наша цель - выбросить побольше приносящих удачу семерок, то дисперсия - не лучший показатель успеха.
Ну хорошо, мы установили, как вычислить дисперсию. Но мы пока не дали ответа на вопрос, почему надо вычислять именно дисперсию. Все так делают, но почему? Основная причина заключается в неравенстве Чебышева которое устанавливает важное свойство дисперсии:
(Это неравенство отличается от неравенств Чебышёва для сумм, встретившихся нам в гл. 2.) На качественном уровне (8.17) утверждает, что случайная величина X редко принимает значения, далекие от своего среднего если ее дисперсия VX мала. Доказательство
тельство необычайно просто. Действительно,

деление на завершает доказательство.
Если мы обозначим математическое ожидание через а стандартное отклонение - через а и заменим в (8.17) на то условие превратится в следовательно, мы получим из (8.17)
Таким образом, X будет лежать в пределах -кратного стандартного отклонения от своего среднего значения за исключением случаев, вероятность которых не превышает Случайная величина будет лежать в пределах 2а от по крайней мере для 75% испытаний; в пределах от до - по крайней мере для 99%. Это случаи неравенства Чебышёва.
Если бросить пару кубиков раз, то общая сумма очков во всех бросаниях почти всегда, при больших будет близка к Причина этого следующая: дисперсия независимых бросаний составит Дисперсия в означает стандартное отклонение всего
Поэтому из неравенства Чебышёва получаем, что сумма очков будет лежать между
по крайней мере для 99% всех бросаний правильных кубиков. Например, итог миллиона бросаний с вероятностью более 99% будет заключен между 6.976 млн и 7.024 млн.
В общем случае, пусть X - любая случайная величина на вероятностном пространстве П, имеющая конечное математическое ожидание и конечное стандартное отклонение а. Тогда можно ввести в рассмотрение вероятностное пространство Пп, элементарными событиями которого являются -последовательности где каждое , а вероятность определяется как
Если теперь определить случайные величины формулой
то величина
будет суммой независимых случайных величин, которая соответствует процессу суммирования независимых реализаций величины X на П. Математическое ожидание будет равно а стандартное отклонение - ; следовательно, среднее значение реализаций,
![]()
будет лежать в пределах от до по крайней мере в 99% временного периода. Иными словами, если выбрать достаточно большое то среднее арифметическое независимых испытаний будет почти всегда очень близко к ожидаемому значению (В учебниках теории вероятностей доказывается еще более сильная теорема, называемая усиленным законом больших чисел; но нам достаточно и простого следствия неравенства Чебышёва, которое мы только что вывели.)
Иногда нам не известны характеристики вероятностного пространства, но требуется оценить математическое ожидание случайной величины X при помощи повторных наблюдений ее значения. (Например, нам могла бы понадобиться средняя полуденная температура января в Сан-Франциско; или же мы хотим узнать ожидаемую продолжительность жизни, на которой должны основывать свои расчеты страховые агенты.) Если в нашем распоряжении имеются независимые эмпирические наблюдения то мы можем предположить, что истинное математическое ожидание приблизительно равно
![]()
Можно оценить и дисперсию, используя формулу
Глядя на эту формулу, можно подумать, что в ней - типографская ошибка; казалось бы, там должно стоять как в (8.19), поскольку истинное значение дисперсии определяется в (8.15) через ожидаемые значения. Однако замена здесь на позволяет получить лучшую оценку, поскольку из определения (8.20) вытекает, что
![]()
Вот доказательство:

(В этой выкладке мы опираемся на независимость наблюдений, когда заменяем на )
На практике для оценки результатов эксперимента со случайной величиной X обычно вычисляют эмпирическое среднее и эмпирическое стандартное отклонение после чего записывают ответ в виде Вот, например, результаты бросаний пары кубиков, предположительно правильных.
Математическим ожиданием случайной величины X называется среднее значение .
1. M(C) = C
2. M(CX) = CM(X) , где C = const
3. M(X ± Y) = M(X) ± M(Y)
4. Если случайные величины X и Y независимы, то M(XY) = M(X)·M(Y)
Дисперсия
Дисперсией случайной величины X называется
D(X) = S(x – M(X)) 2 p = M(X 2 ) – M 2 (X) .
Дисперсия представляет собой мерой отклонения значений случайной величины от своего среднего значения.
1. D(C) = 0
2. D(X + C) = D(X)
3. D(СX) = C 2 D(X) , где C = const
4. Для независимых случайных величин
D(X ± Y) = D(X) + D(Y)
5. D(X ± Y) = D(X) + D(Y) ± 2Cov(x, y)
Квадратный корень из дисперсии случайной величины X называется средним квадратичным отклонением ![]() .
.
@ Задача 3 : Пусть случайная величина X принимает всего два значения (0 или 1) с вероятностями q, p , где p + q = 1 . Найти математическое ожидание и дисперсию.
Решение:
M(X) = 1·p + 0·q = p; D(X) = (1 – p) 2 p + (0 – p) 2 q = pq.
@ Задача 4 : Математическое ожидание и дисперсия случайной величины X равны 8. Найти математическое ожидание и дисперсия случайных величин: а) X – 4 ; б) 3X – 4 .
Решение: M(X – 4) = M(X) – 4 = 8 – 4 = 4; D(X – 4) = D(X) = 8; M(3X – 4) = 3M(X) – 4 = 20; D(3X – 4) = 9D(X) = 72.
@ Задача 5 : Совокупность семей имеет следующее распределение по числу детей:
| x i | x 1 | x 2 | ||
| p i | 0,1 | p 2 | 0,4 | 0,35 |
Определить x 1 , x 2 и p 2 , если известно, что M(X) = 2; D(X) = 0,9 .
Решение: Вероятность p 2 равна p 2 = 1 – 0,1 – 0,4 – 0,35 = 0,15. Неизвестные x находятся из уравнений: M(X) = x 1 ·0,1 + x 2 ·0,15 + 2·0,4 + 3·0,35 = 2; D(X) = ·0,1 + ·0,15 + 4·0,4 + 9·0,35 – 4 = 0,9. x 1 = 0; x 2 = 1.
Генеральная совокупность и выборка. Оценки параметров
Выборочное наблюдение
Статистическое наблюдение можно организовать сплошное и не сплошное. Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности (генеральной совокупности). Генеральная совокупность это множество физических или юридических лиц, которую исследователь изучает согласно своей задачи. Это часто экономически невыгодно, а иногда и невозможно. В связи с этим изучается только часть генеральной совокупности – выборочная совокупность .
Результаты, полученные на основе выборочной совокупности, можно распространить на генеральную совокупность, если следовать следующим принципам:
1. Выборочная совокупность должна определяться случайным образом.
2. Число единиц выборочной совокупности должно быть достаточным.
3. Должна обеспечиваться репрезентативность ( представительность) выборки. Репрезентативная выборка представляет собой меньшую по размеру, но точную модель той генеральной совокупности, которую она должна отражать.
Типы выборок
В практике применяются следующие типы выборок:
а) собственно-случайная, б) механическая, в) типическая, г) серийная, д) комбинированная.
Собственно-случайная выборка
При собственно-случайной выборке отбор единиц выборочной совокупности производится случайным образом, например, посредством жеребьевки или генератора случайных чисел.
Выборки бывают повторные и бесповторные. При повторной выборке единица, попавшая в выборку, возвращается и сохраняет равную возможность снова попасть в выборку. При бесповторной выборке единица совокупности, попавшая в выборку, в дальнейшем в выборке не участвует.
Ошибкиприсущие выборочному наблюдению, возникающие в силу того, что выборочная совокупность не полностью воспроизводит генеральную совокупность, называются стандартными ошибками . Они представляют собой среднее квадратичное расхождение между значениями показателей, полученных по выборке, и соответствующими значениями показателей генеральной совокупности.
Расчетные формулы стандартной ошибки при случайном повторном отборе следующая: , а при случайном бесповторном отборе следующая: ![]() , где S 2 – дисперсия выборочной совокупности, n/N –
доля выборки, n, N
- количества единиц в выборочной и генеральной совокупности. При n = N
стандартная ошибка m = 0.
, где S 2 – дисперсия выборочной совокупности, n/N –
доля выборки, n, N
- количества единиц в выборочной и генеральной совокупности. При n = N
стандартная ошибка m = 0.
Механическая выборка
При механической выборке генеральная совокупность разбивается на равные интервалы и из каждого интервала случайным образом отбирается по одной единице.
Например, при 2%-ной доли выборки из списка генеральной совокупности отбирается каждая 50-я единица.
Стандартная ошибка механической выборки определяется как ошибка собственно-случайной бесповторной выборки.
Типическая выборка
При типической выборке генеральная совокупность разбивается на однородные типические группы, затем из каждой группы случайным образом производится отбор единиц.
Типической выборкой пользуются в случае неоднородной генеральной совокупности. Типическая выборка дает более точные результаты, потому что обеспечивается репрезентативность.
Например, учителя, как генеральная совокупность, разбиваются на группы по следующим признакам: пол, стаж, квалификация, образование, городские и сельские школы и т.д.
Стандартные ошибки типической выборки определяются как ошибки собственно-случайной выборки, с той лишь разницей, что S 2 заменяется средней величиной от внутригрупповых дисперсий.
Серийная выборка
При серийной выборке генеральная совокупность разбивается на отдельные группы (серии), затем случайным образом выбранные группы подвергаются сплошному наблюдению.
Стандартные ошибки серийной выборки определяются как ошибки собственно-случайной выборки, с той лишь разницей, что S 2 заменяется средней величиной от межгрупповых дисперсий.
Комбинированная выборка
Комбинированная выборка является комбинацией двух или более типов выборок.
Точечная оценка
Конечной целью выборочного наблюдения является нахождение характеристик генеральной совокупности. Так как этого невозможно сделать непосредственно, то на генеральную совокупность распространяют характеристики выборочной совокупности.
Принципиальная возможность определения средней арифметической генеральной совокупности по данным средней выборки доказывается теоремой Чебышева . При неограниченном увеличении n вероятность того, что отличие выборочной средней от генеральной средней будет сколь угодно мало, стремится к 1.
Это означает, что характеристика генеральной совокупности с точностью . Такая оценка называется точечной .
Интервальная оценка
Базисом интервальной оценки является центральная предельная теорема .
Интервальная оценка позволяет ответить на вопрос: внутри какого интервала и с какой вероятностью находится неизвестное, искомое значение параметра генеральной совокупности?
Обычно говорят о доверительной вероятности p = 1 – a, с которой будет находиться в интервале – D < < + D, где D = t кр m > 0 предельная ошибка выборки, a - уровень значимости (вероятность того, что неравенство будет неверным), t кр - критическое значение, которое зависит от значений n и a. При малой выборке n < 30 t кр задается с помощью критического значения t-распределения Стъюдента для двустороннего критиерия с n – 1 степенями свободы с уровнем значимости a (t кр (n – 1, a) находится из таблицы «Критические значения t–распределения Стъюдента», приложение 2). При n > 30, t кр - это квантиль нормального закона распределения (t кр находится из таблицы значений функции Лапласа F(t) = (1 – a)/2 как аргумент). При p = 0,954 критическое значение t кр = 2 при p = 0,997 критическое значение t кр = 3. Это означает, что предельная ошибка обычно больше стандартной ошибки в 2-3 раза.
Таким образом, суть метода выборки заключается в том, что на основании статистических данных некоторой малой части генеральной совокупности удается найти интервал, в котором с доверительной вероятностью p находится искомая характеристика генеральной совокупности (средняя численность рабочих, средний балл, средняя урожайность, среднее квадратичное отклонение и т.д.).
@ Задача 1. Для определения скорости расчетов с кредиторами предприятий корпорации в коммерческом банке была проведена случайная выборка 100 платежных документов, по которым средний срок перечисления и получения денег оказался равным 22 дням ( = 22) со стандартным отклонением 6 дней (S = 6). С вероятностью p = 0,954 определить предельнуюошибку выборочной средней и доверительный интервал средней продолжительности расчетов предприятий данной корпорации.
Решение: Предельнаяошибка выборочной средней согласно (1) равна D = 2· 0,6 = 1,2, а доверительный интервал определяется как (22 – 1,2; 22 + 1,2), т.е. (20,8; 23,2).
§6.5 Корреляция и регрессия
Математическое ожиданиеДисперсия
непрерывной случайной величины X , возможные значения которой принадлежат всей оси Ох, определяется равенством:
![]()
Назначение сервиса . Онлайн калькулятор предназначен для решения задач, в которых заданы либо плотность распределения f(x) , либо функция распределения F(x) (см. пример). Обычно в таких заданиях требуется найти математическое ожидание, среднее квадратическое отклонение, построить графики функций f(x) и F(x) .
Инструкция . Выберите вид исходных данных: плотность распределения f(x) или функция распределения F(x) .
Задана плотность распределения f(x): 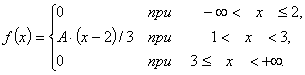
Задана функция распределения F(x): 
Непрерывная случайна величина задана плотностью вероятностей 
(закон распределения Релея – применяется в радиотехнике). Найти M(x) , D(x) .
Случайную величину X называют непрерывной
, если ее функция распределения F(X)=P(X < x) непрерывна и имеет производную.
Функция распределения непрерывной случайной величины применяется для вычисления вероятностей попадания случайной величины в заданный промежуток:
P(α < X < β)=F(β) - F(α)
причем для непрерывной случайной величины не имеет значения, включаются в этот промежуток его границы или нет:
P(α < X < β) = P(α ≤ X < β) = P(α ≤ X ≤ β)
Плотностью распределения
непрерывной случайной величины называется функция
f(x)=F’(x) , производная от функции распределения.
Свойства плотности распределения
1. Плотность распределения случайной величины неотрицательна (f(x) ≥ 0) при всех значениях x.2. Условие нормировки:
Геометрический смысл условия нормировки: площадь под кривой плотности распределения равна единице.
3. Вероятность попадания случайной величины X в промежуток от α до β может быть вычислена по формуле
Геометрически вероятность попадания непрерывной случайной величины X в промежуток (α, β) равна площади криволинейной трапеции под кривой плотности распределения, опирающейся на этот промежуток.
4. Функция распределения выражается через плотность следующим образом:
Значение плотности распределения в точке x не равно вероятности принять это значение, для непрерывной случайной величины речь может идти только о вероятности попадания в заданный интервал. Пусть }










